A Closer Look at the Vector Space Model
Preparing the Documents
Before VSM can be used to process any queries, all documents must be prepared. A giant term by document matrix is created where the columns represent web documents and the rows represent terms. If a document contains a term, the corresponding row of that vector will have a 1, otherwise there will be a 0.
For example, lets look at the survey you took earlier. We can use the information in your survey to create a "term-by-employee" vector by placeing a 1 next to the terms you selected and a 0 next to the terms you did not select.
| Coffee | (0 or 1) |
| Tea | (0 or 1) |
| Donuts | (0 or 1) |
| Muffins | (0 or 1) |
| Morning | (0 or 1) |
| Evening | (0 or 1) |
| Monday | (0 or 1) |
| Tuesday | (0 or 1) |
| Wednesday | (0 or 1) |
| Thursday | (0 or 1) |
| Friday | (0 or 1) |
| 12:00 | (0 or 1) |
| 1:00 | (0 or 1) |
| Kickball | (0 or 1) |
| Trivia | (0 or 1) |
Combine your vector with those of the other employees around you to create a term-by-employee matrix, much, much smaller but very similar to the term-by-document matrix representing the entire World Wide Web.
So why is it useful to convert the web into a matrix? Well, it just so happens that mathematicians know a great deal about the properties of matrices, and so we can use this knowledge to learn the properties of the world wide web.
Processing a Query
When a user enters a query in the search engine, the computer converts the query into a vector the same way it converted the web documents. Then it uses linear algebra to find the document closest to the vector.
Activity 2.1
To help better understand how it does this, lets look at our term-by-employee matrix again, and in order to get a better visual of the process let's only consider the vector space created by the Coffee, 12:00, and Kickball rows of the matrix.
Since our matrix now only has three dimensions, we can plot each employee's vector in a 3-dimensional space. Let Coffee be the X-axis, 12:00 be the Y-axis, and Kickball be the Z-axis. Fold a piece of graph paper as shown:
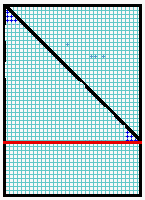 Make sure the piece of paper is square and cut along the red line as shown.
Make sure the piece of paper is square and cut along the red line as shown.
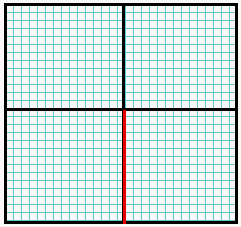 Fold the square in half twice to form a horizontal and vertical crease through the middle, then cut along the red line as shown.
Fold the square in half twice to form a horizontal and vertical crease through the middle, then cut along the red line as shown.
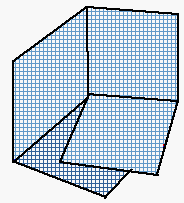 Align flaps so that one is on top of the other (it doesn't matter which) as shown.
Align flaps so that one is on top of the other (it doesn't matter which) as shown.
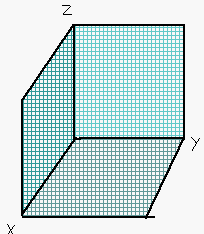 Now you should have a cube-like structure made out of graph paper representing the non-negative quadrant of R³. Label your X, Y, and Z axes.
Now you should have a cube-like structure made out of graph paper representing the non-negative quadrant of R³. Label your X, Y, and Z axes.
Now that you have your 3-D graph, use pipe-cleaners to graph each of the vectors representing employees.
What if you were a employee who enjoys coffee and kickball, and you would like to find a co-worker who shares your interests. Create a 3-dimensional query vector representing a query for Coffee and Kickball (so the vector should be [1 0 1]). Which employee do you think is the closest match? Is the answer obvious? Try other queries.
This method, though it may seem good enough for now, is not quite precise enough for our liking, and is also impossible once we move into four or more dimensions. So let's look at a more mathematical method.
Any vector can be summarized by its length and its angle relative to another fixed vector. Once we know the length of two vectors x and y, we can easily find the cosine of the angle between them with the following formula:
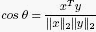
If the vectors are parallel (they are very related), the cosine of their angle will be 1. If the vectors are orthogonal (they are unrelated), the cosine of their angle will be 0.
Find the cosines of the angles between all of the employee vectors and two or three of your query vectors. Which employees best match the query? Were your guesses correct?
One of the main advantages of the Vector Space Model is that we can make it more complex without greatly complicating the calculations. For example, the method works as well in millions of dimensions as it did in our tiny three dimension example (though the calculations would take considerably longer).
Of course, once we start working with millions of terms and millions of documents, it may become harder to discern which documents should be considered relevant. One solution to this problem is to add weights to terms when indexing. There are several ways to weight the terms in a document, but one very good example is to weight the terms by percentage of relevance.
For example, say you were indexing a garden article that talked about the different fertilizers that mentioned special types of fertilizers for gardenias and roses. We would certainly want to signify "fertilizer," rose," and "gardenia" as important terms for the document, but assigning the vector:  misrepresents the document. The term "fertilizer" should certainly carry more weight. Instead we might want a vector that looked more like:
misrepresents the document. The term "fertilizer" should certainly carry more weight. Instead we might want a vector that looked more like: 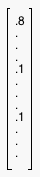 . This vector tells us that 80 percent of the article pertains to fertilizer, while only 10 percent pertains to both roses and gardenias. This is certainly a much more accurate representation our document.
. This vector tells us that 80 percent of the article pertains to fertilizer, while only 10 percent pertains to both roses and gardenias. This is certainly a much more accurate representation our document.
When working with such a large number of documents, we might also face a problem of too many documents being returned to answer a query. This could be daunting for a hapless searcher, but also wastes time for the search engine. A cut-off point seems appropriate. Luckily for us this is not hard to execute with the VSM.
To set our cut-off value, we can simply tell our search engine not to return any documents whose angle with the query is greater than, say, 45 degrees (or cosine values less than .7071). If we were to make an image of this 45 degree cut-off, it would look something like this:
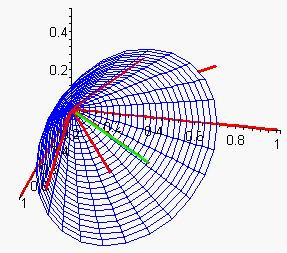 (image from Langville)
(image from Langville)
Activity 2.2
To get a better idea of what a cut-off would look like in three dimensions, take another piece of paper and create a cut-off cone for the coffee and kickball query in the three-dimensional term-by-employee vector space. First make a cone for the 45 degree cut-off (like in the picture shown above). Are any employees cut-off? Now make 30 degree and 15 degree cut-off cones and compare the results with the first one. Are these cut-offs useful?
Flaws of the Vector Space Model
What more could we want in a search engine? The Vector Space Model seems like a watertight method so far. True, the VSM seems to be the best search engine model we have seen so far, but it is far from perfect.
Since there are more than 3 billion documents on the web, a search engine using the vector space model would have to calculate more than 3 billion angle measures for every single query. Then of course all of the documents returned (and aren't cut-off) must be ranked for the user. And ideally this should all happen in less than a second. This of course is not possible. So what can we do?
Luckily we have been saved from our plight by the process of singular value decomposition. So, we should probably take some time to learn all about this powerful tool.
Back to Top!
Next Page!
Previous Page!
Or Jump to a page!letter 1 2 3 4 5 6
This material is based upon work supported by the National Science Foundation under Grant No. 0546622. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.