(All information was taken from an interview with Page and Brin in Wired Magazine)
In the summer of 1995, a second year graduate student of Stanford University was giving tours to new students of the program. While giving one of these tours, Sergey Brin met new student Larry Page. Page and Brin did not exactly hit it off right away, but soon came to enjoy the intelligent banter.
Page and Brin
Page, after trying on a few different areas of studies, found that his choice of a human-computer interaction advisor suited him well. Page stated that he was immediately drawn to the web because of its mathematical characteristics as well as its vastness. He saw that each page could be represented as a node and each hyperlink as an edge between nodes. This excited and motivated him because "computer scientists love graphs." From the idea of the web being an enormous graph grew the theories of its link structure. Soon, Page decided that the link structure of the web would be the focus of his doctoral thesis.
The science of bibliometrics helped Page to think of the idea of Backrub (his term for the bibliometrics of the web). Authors in the hard sciences consider being cited just as important as being published. Papers are not only judged on content, but also on the number of papers they cite and the number of papers that site them. Backrub worked in the same way but for pages on the web.
Page reasoned that a hyperlink is a type of citation. If site A links to site B, then we can think of site A as referencing site B (or, as in Activity 00309-01, site A voted for the validity of site B). At the time of Page's idea, there were around 10 million documents on the web with an unknown number of hyperlinks. Thus, Page needed some way to count the links within the pages, so he began to build a crawler. Brin, lured by the complexity and scale of Page's problem, decided to also do his doctoral thesis on this subject, and thus joined Page in the Backrub efforts.
In 1996, Page and Brin started their crawler on Page's Stanford homepage and it worked outward from there, gathering data about context and hyperlinks from random pages. After a substantial amount of data was gathered, the web graph revealed not just who linked to whom, but the importance of who linked to whom. Links to the page would help find the page's rank.
A page's PageRank is found, ultimately, by counting its in-links and in-links to those in-links, and so on. This gave the Backrub idea the recursive quality to which Brin, a recognized math prodigy by middle school, applied his mathematical know-how.
The PageRank system rewards for links from important sources and penalizes for links from less important sites. For example, we can imagine that there are hundreds of pages linking to a page on IBM.com, but should a link from Intel have the same weight as a link from a teen's homepage?
In the picture above, there are many pages referencing IBM and Intel, but only a couple of Johnny's friends linking to his homepage. Also, notice Intel and IBM only have a few out-links (probably to other well referenced pages), but Johnny has more out-links than in-links. But what does this mean to a crawler that knows nothing of Intel, IBM, or Johnny?
Another example is in applying for employment. One recommendation letter from Donald Trump should help more with a resume than twenty from unknown people. However, if the company finds that Donald Trump freely gives recommendations to anyone who emails him, then his recommendation should drop drastically in its weight. (Trump example taken from a book by Langville and Meyer)
Concept Check # 3:
If you knew nothing of IBM, Intel, or Johnny, how would you decide their importance to users based on the picture?
When Page and Brin released the crawler and collected the data for the Backrub algorithm, it already worked like a search engine. It constantly organized a list of back-links that were ranked by importance. Now they just needed to give it a name and make it user-friendly. They came up with the name Google (from the word googol, a 1 and 100 zeros), because of the way Backrub worked. The larger the web, the better the engine!
This was an innovative way of searching the web that quickly took off. Other search engines before Google were not considering the PageRank of a site, but such things as text, heading, and frequency of selection by users (which Google still takes into account - but with less weight than PageRank). Thus, when Google's maiden voyage began in August of 1996 on the Stanford website, it immediately became huge. It would often crash Stanford's service (which is one of the best-networked institutions in the world). Page's dorm room was made into the computer lab (where they kept the Frankenstein computer made from spare parts). Brin's room was made into the office and programming center. Finally, in 1997, Page and Brin quit Stanford to pursue the business of Google.
Concept Check # 4:
Give a summary of PageRank and the idea behind Google.
To see the PageRank of actual pages on the web, you can download the Google toolbar here (Requires Mozilla Firefox browser). Click here to see a screen shot of the toolbar (with a full PageRank for Google.com - obviously!)
Now that you understand the idea of PageRank, we would like to test your mathematical knowledge by explaining how PageRank works. This will help us to assess your ability to understand the sciences compared to the average user. Again, your information will not be shared, but is merely to help us improve the user-friendliness of the web.
This material is based upon work supported by National Science Foundation under Grant No. 0546622.
Any opinions, findings, and conclusions or recommendations expressed in this material are those of the
author and do not necessarily reflect the views of the National Science Foundation.
 Page and Brin
Page and Brin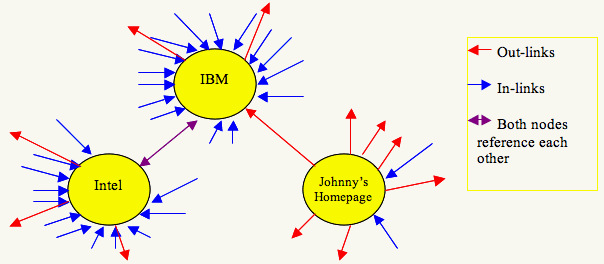
{kind=link}