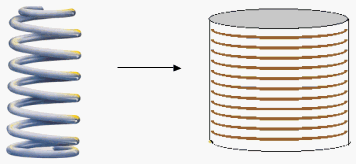
(Figure 1. The string of text is wrapped into a cylinder shape so that the letters line up into columns)
As I mentioned on the previous page, Eliyahu Rips attempted to defend (even prove) the existence of the Bible Code mathematically in his paper "Equidistant Letter Sequences in the Book of Genesis," which was co-written by Witzum and Rosenburg, and was published by the Journal of Statistical Science in 1994. Of course, the paper was also reprinted in every copy of Michael Drosnin's Bible Code, which makes this "possibly the most reprinted scientific paper of all time" McKay.
Since this paper provides such crucial support for the Bible Code hypothesis, perhaps we should take some time to examine it a little closer.
What do Rips and his co-authors (who will be referred to collectively as hereafter) hope to prove with their paper?
The paper basically outlines an experiment they conducted by collecting a sample of pairs of words (consisting of names of famous Jewish Rabbis with either their date of birth or date of death), and then comparing the distances of pairs in Genesis with the distances of the same set of pairs in another text. WRR find that the distances between word pairs in Genesis were significantly smaller than the distances between these same word pairs in any of the other control texts.
Their claim, then, is that finding such small distances between word pairs is so unlikely (i.e. P(distance small)= very very small), that the words could not have been placed there by chance (which implies, of course, that the words were placed, or encoded, by a higher power)
Although, this claim raises several important questions, we will explore those which concern WRR's measure of distance and their experimental methods.
First, imagine the text (such as the text of Genesis) as one long strand of letters and words that has been wrapped up like a spiral or a coil to look like a cylinder (the width of this cylinder will be discussed later).
Then if we cut the cylinder between two columns, we can spread it out like an array.
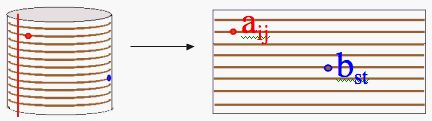
In this array, each letter has its own set of indices (row number and column number) which can be used to find a Euclidean distance.
In the equation below, d(a,b) represents the Euclidean distance between points a and b from the above illustration.
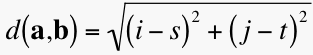 .
.One issue that arises is where to cut the cylinder. Obviously, there are an infinite number of places where the cut could be made. Interestingly, it turns out that no matter how many different cuts you make, there will only be two possible distances between any two letters. Why is this? The best explanation is to see it for yourself.
For this activity you will need:
Now that we know how WRR finds the distance between two letters of a text, we must find out WRR's definition of distance between two ELSs (lets call them ELS1 and ELS2. For this definition we need three things:
The following picture should help explain what each of these component distances look like.
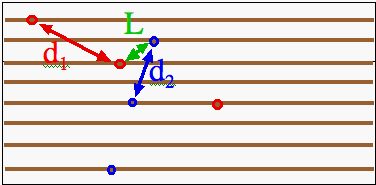
WRR give the following definition for the total distance between two ELSs.
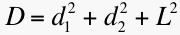 .
.Another question you might have is, "What about the size of the array? How do you decide how many columns it should have?" This is a very good question, too.
The number of columns, denoted by h, defines the size of an array formed by the process we described in Figure 2. So, we can let Dh denote the distance between two ELSs in an array with h columns. The authors then take the sum of these Dhs for h equal to 1 through 10.
Now that we have a reasonable understanding of how the authors measure distance between ELSs, we can begin to use our intuition and statistical "know how" to expose some of its flaws.
What do you think about this distance measure?
Do you think it is accurate?
Does it make sense to you to use a Euclidean distance?
One problematic element of the measure employed by WRR is the incorporation of the cylinder. The distance is not defined simply as a skip distance, or even as a Euclidean distance on an array of fixed size. Instead the text is allowed to move around on a cylinder!
Futhermore, the size of the cylinder is not even fixed. The number of columns is allowed to change from 1 to 10.
How do you think these extra possibilities affect the distance measures? With this much allowance, is it likely to get small distances more often or less often?
Take a look for yourself at the distribution of distances!
Note: The following and later activities in this module use MATLAB. Before you continue with this activity, we recommend at least browsing through this MATLAB tutorial.
The following MATLAB codes allow you to input a string (without spaces or punctuation) in which it will search for randomly generated pairs of words, and plot their distances with a histogram.
Download each of the following mfiles.
histdata.m
Delta.m
ELS.m
makearray.m
Once you've downloaded the code, make sure it shows up in your current directory before you try to run it (see illustrations below).
![]()
![]()
![]()
Input a string of random letters. You can try different lengths; start with at least 50 letters, and then work up to whatever length you think your computer can handle.
Ignoring the bar over zero, as those are actually unfound word pairs,
Compare your histogram results to those of your classmates.Now we will move on to consider the experimental methods used by WRR.