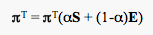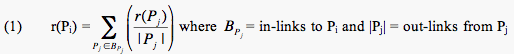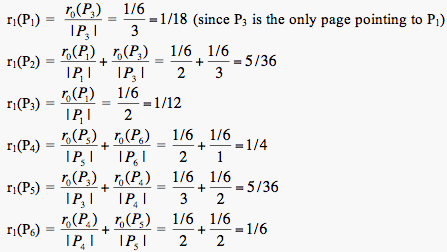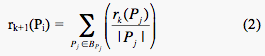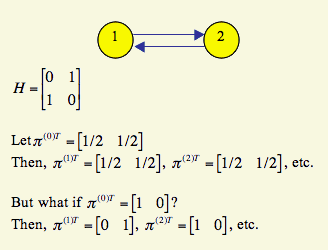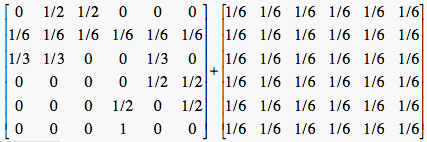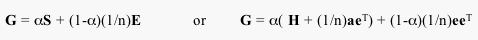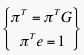Because of spamming, previous search engines were sinking fast. However, when the link analysis model of Google came along, the search engine business was saved. The recommendation system helped Google to realize the importance of each hyperlink (as discussed previously) and thus helped them to depend far less on context. That is, Google found that a webpage is important if other important pages point it.
The genius of this statement is that Google's ranking system is query-independent. This is important because there is an index of the recent ranking of the 8.1 billion pages. However, there also seems to be a problem with Google's thesis since it is a circular definition. How can you find the importance of a page by its in-links if you have to know the in-links of the in-links, and so on? As you will learn, it all boils down to a beautifully simple formula.
When mathematician Heinrich Hertz was asked, "What makes an equation great?" he stated that:
One cannot escape the feeling that these mathematical formulae have an independent existence and an intelligence of their own, that they are wiser than we are, wiser even than their discoverers, that we get more out of them than was originally put into them.
While the PageRank equation does not appear in the book, It Must Be Beautiful: Great Equations of Modern Science, it certainly deserves praise for its simplicity.
Please take a few minutes to memorize this equation. We would like to test you on an explanation of the parts at a later point.
Now we need to explain how a circular definition boils down to such a simple equation.
The Beauty of PageRank
Let r(Pi) represent the PageRank of page i. Then, since PageRank is based on the importance of sites pointing to your site, r(Pi) is the sum of the PageRanks of all pages pointing into page i. So,
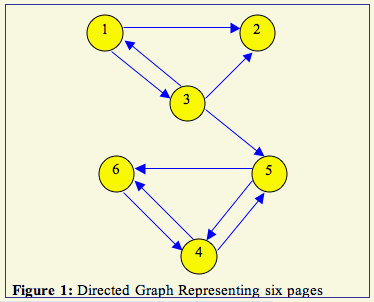
We then use an iterative process by beginning with all n pages having an equal rank of 1/n. For Figure 1, at iteration 0 we have the page ranks of:
We can now write equation (1) as an iterative procedure:
But, this is a lot of work by hand, so we can use matrices to simultaneously find the PageRanks of all pages. The current PageRank is stored as the 1xn vector π(k+1)T (where the iteration is k+1) and the previous PageRank is stored as π(k)T (where the previous iteration is k).
So, for Figure 1, π(2)T = [.0278, .0556, .0278, .2361, .1250, .1944].
To arrive at this π(k)T, we must have a matrix to put into our equation. As you saw with Activity 00309-01, we start with a record of the voting matrix A.
Activity 00309-03: Matrices
Purpose: To create the voting matrix A, and the row-stochastic matrix H for Figure 1.
Materials: Paper and writing utensil
Estimated Time: 5 minutes
Instructions: Use Figure 1 to create a voting matrix A. Then, create a row-stochastic (for non-zero rows) matrix H(example).
(Note: You can check your matrix H in the answer of Concept Check # 6.)
1. At each iteration, there is only a vector-matrix multiplication, so the computational effort is minimal.
2. H is an extremely sparse matrix since most pages only link to a handful of other webpages. This makes observation 1 even nicer (as you saw in Concept Check # 6). Also, the storage of sparse matrices is smaller than regular matrices since only the non-zero elements need to be stored.
3. The iterative process is a simple linear stationary process and is the classical power-method applied to H.
4. H is a lot like the stochastic transition probability matrix of a Markov chain. H is actually substochastic since it has some rows that sum to 0, but the rest sum to 1. The rows with sum 0 are called dangling nodes, and can cause problems for PageRank, as we will see later.
While these observations are useful in finding the PageRank, there are some questions about the iterative process that we must first address.
1. Will this iterative process continue indefinitely or will it converge?
2. Under what properties of H is it guaranteed to converge?
3. If it does converge, will it converge to something meaningful in the context of PageRank?
4. Does the convergence depend on the starting vector π (0)T?
5. If the series converges, after how many iterations will this take place?
When Brin and Page began to think about these questions, they started with π(0)T=(1/n)eT, where eT is a 1xn vector of all ones. This seems intuitively fair since when you start, every page must have equal opportunity to be the most important.
However, when they ran the power method on equation (3), they found that there were rank sinks (where the PageRank vector would have one page with PageRank 1 and the rest 0). Dangling nodes (like node 2 in Figure 1) and dangling clusters (like the cluster 4- 5-6 in Figure 1) were the cause of these rank sinks. You can better understand this idea by thinking of the "flow" of the graph. Eventually, all importance flows to page 2 or the cluster 4-5-6.
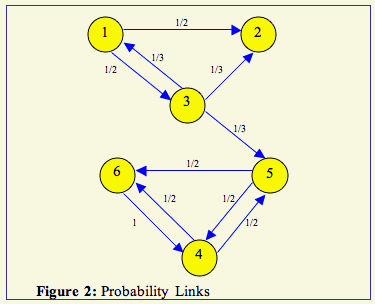
Another problem occurred in cycles. Consider the example below:
Furthermore, we would like the PageRank vector to be independent of π (0)T.
So, with a few minor adjustments, we can fix both of these problems.
If we can make H into a transition probability matrix, then we will have a Markov chain that will give not only fix these problems, but will give answers to the questions above.
The Random Surfer Idea
Activity 00309-04: Random Surfer
Purpose: To understand the idea of the random surfer on the web and what happens in cycles and dangling nodes. To determine a way to fix the graph so that problems of dangling nodes and cycles do not occur.
Materials: 6 sheets of paper labeled 1 - 6, masking tape, 6-sided die, paper, and writing utensil
Estimated Time: 10 minutes
Instructions:
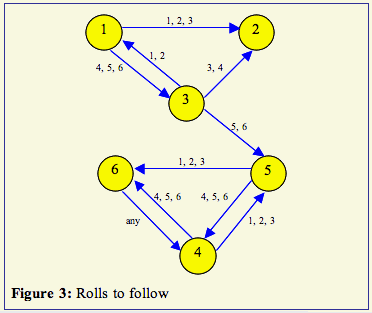
1. Using the papers labeled 1 - 6 and the masking tape, make the graph of Figure 1 on the floor. Be sure you make the arrows and not just lines between the nodes.
2. Start by standing on any node you want. Record your starting node on your paper.
3.
If you are on a node with 0 out-links, then there is zero probability of following a hyperlink, so record this and then start the activity again on a different node.
If you are on a node with 1 out-link, then there is a 100% chance of you following that link, so take the link and record the node on which you are now standing.
If you are on a node with 2 out-links (there is a 50% chance of going to either node): if you roll 1 - 3, go left and if you roll 4 - 6, go right. Record the node on which you are now standing.
If you are on a node with 3 out-links (there is a 33.3% chance of going to any of the 3 nodes): if you roll a 1 or 2, take the left-most link; if you roll a 3 or 4, take the middle link; if you roll a 5 or 6, take the right-most link.
Here is a picture with the links not having probabilities (as in Figure 2), but with what number you roll to follow that link:
4. Stop when there is a problem or you recognize a trend.
5. Repeat the steps with a few different starting points.
Subject 1:
Start: Node 3
Rolled 6, so go to Node 5
Rolled 5, so go to Node 4
Rolled 4, so go to Node 5
Rolled 4, so go to Node 6
Go to Node 4
Rolled 3, so go to Node 6
Go to Node 4
Rolled 2, so go to Node 6
Go to Node 4
Trend: Stuck in cycle of nodes 4, 5, and 6.
Nodes 4 and 6 are more important than node 5
Restart: Node 1
Rolled 6, so go to Node 3
Rolled 3, so go to Node 2
Stuck at node 2
Note: You do not need to write all the information about the transitions like Subject 1. Just recording the nodes on which you landed is sufficient.
Questions:
1. What happened in your activity?
2. How do you think these problems could be fixed? Think about a surfer on the web who randomly clicks on hyperlinks but ends up at a dead-end or stuck in a cycle, what could he/she do?
We would like all pages to at least have some chance of being seen. We also would like for our random surfer to not get stuck anywhere and quit. We could fix this specifically for our small web graph of Figure 2 by adding a bi-directional link from node 5 to node 2, but think about the web on a large scale. First, what does this mean to add a bi-directional link? It means we would have to physically go to those pages and and links. We would also have to change the rows of H for 2 and 5 since they would now have a new out-link. Furthermore, it is infeasible to look at the graph and find the dangling nodes and cycles and then find where we could put a link to fix them. So, instead, if we thought of the random surfer idea again, we can see a meaningful way to change the graph.
If you are stuck on a page with no hyperlinks, you have no choice but to type a new address in the URL bar or to hit the back button (which would be the same as typing the previous page's address in the bar). So, if we add a link from node 2 to every other node, we would fix the dangling node problem in Figure 2.
What probability should every out-link of page 2 have? Brin and Page decided to give each out-link equal probability since you could be equally likely to type any page's address in the URL bar. So, now our graph looks like:
How could we easily fix this dangling node problem mathematically? That is, without erasing row 2 of matrix H and writing in 1/6 for each of its entries, how can we make row 2 have 1/6 for each entry?
If we add a matrix of all zeros except for 1/n in the entries of rows whose sum was zero in H, we will fix the dangling node problem.
That is,
S = H + (1/n)aeT, where a is an nx1 vector with entries of 1 in rows where H has row sums of zero.
For Figure 2, this would be:
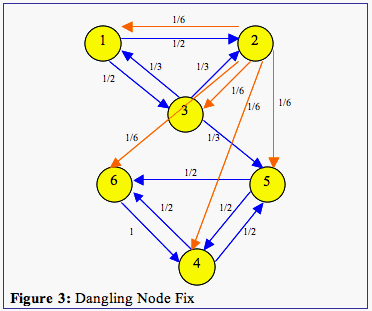
This does not make the computational work much more than before since it is only a rank-one update. However, as we can see from Figure 3, that this still does not fix the cycle problem since we can still get stuck in the cycle of nodes 4, 5, and 6.
Again, the reasoning of a random surfer will help us understand how to fix this. It is the same idea as the dangling node fix, but we can now think of an intelligent surfer. If you are surfing the web by following hyperlinks, you will either get bored at some point or decide that this path is not taking you where you want to go. Hence, you can go to the URL bar and type any page's address you wish.
Concept Check # 7:
What does fixing the cycles mean for the graph in Figure 3?
Mathematically, again, we cannot go to the picture and add a link from a node to only the nodes where a link does not exist. So, we must add a link to each page even if one already exists. Now, since there is an equal chance you will type any page's address in the URL bar, we must add 1/n to each element of S.
But, should equal weight be given to the hyperlink matrix, S and the matrix we are using to fix the cycles? Generally, if you were just surfing the web, then you would most likely follow hyperlinks. Google chose to depend 85% on the web structure and 15% on the URL bar. That is,
Now, in general terms, for any graph, we have the Google matrix G
Where (1/n)E = (1/n)eeT is sometimes referred to as the teleportation matrix (since a surfer can "teleport" from a page to any other page using the URL bar).
Summary of Symbols:
H
very sparse, raw sub-stochastic hyperlink matrix
S
sparse, stochastic, most likely reducible matrix
G
completely dense, stochastic, primitive matrix called the Google matrix
E
completely dense, rank-one teleportation matrix
n
number off pages in the engine's index (also size of all matrices)
α
scaling parameter between 0 and 1
πT
stationary row vector of G called the PageRank vector
a
binary dangling node vector
Concept Check # 8:
What would it mean to make α=0.60?
Now, we can see from the example and from the equation that the rows of G sum to 1, so all rows of G are row-stochastic. But what about the questions we asked before? Will it converge, does it matter where we start, etc.?
Markov chains, as mentioned before, have nice properties we would like to apply. The extremely important property we need is as follows:
For any starting vector, the Power Method applied to a Markov matrix P converges to a unique positive vector (called the stationary vector)
as long as P is stochastic,irreducible, and aperiodic.
The Google matrix meets all these requirements, and thus most of our answers are found:
1. Will this iterative process continue indefinitely or will it converge? It will converge to a unique positive stationary vector πT (provided we use G and the Power Method).
2. Under what properties of H is it guaranteed to converge? When H is converted to G, it will be stochastic, aperiodic, and irreducible.
3. If it does converge, will it converge to something meaningful in the context of PageRank? πT is a unique positive stationary vector - which means (since all entries are positive) that the entries will be meaningful.
4. Does the convergence depend on the starting vector π(0)T? πT does not depend on the starting vector.
5. If the series converges, after how many iterations will this take place? Still needs to be answered.
Now that we have these nice properties of G, how do we find πT?
The Markov chain property says that by using the Power Method, we then get the unique πT.
Finding πT
We know already that we can find πT by applying the Power Method to πTG and that we want the rows of πT to sum to 1. Hence, we can write this as the system of equations:
The first equation is an eigenvector equation where λ=1.
That is, λπT=πTG. Hence, we are finding the dominant left-hand eigenvector of G corresponding to the dominant eigenvalue of λ1=1.
We could find this vector using Matlab's "eig" command.
Activity 00309-05: Using "eig" in Matlab
Purpose: To find G by hand. Then, to find the left-hand eigenvector of G corresponding to the dominant eigenvalue of λ1=1 for Subject 1's Activity 00309-01 matrix.
5. Clear the Command Window by right-clicking in the command window and selecting "clear command window."
6. Enter G into Matlab.
7. Now type:
[V, Lambda]=eig(G') into the command window and press enter.
V is a matrix of the eigenvectors
Lambda is a diagonal matrix of eigenvalues.
8. Find the column number of the eigenvalue in Lambda that is 1 (or nearly 1).
9. π is the eigenvector in V corresponding to the column in Lambda with 1 as the eigenvalue.
10. Verify that the rankings (not values, but places) are the same as in Activity 00309-01.
For billions of webpages, relying on Matlab's coding is not the fastest method for finding πT. There are over a dozen methods for finding the stationary vector, but the Power Method is the oldest and simplest. However, this method is generally slowest of all the methods, so why would Google use it?
1. Elementary programming - Simple is best when programming an algorithm to run matrices with orders in the billions
- The more simple the algorithm, the less storage required for the algorithm itself
2. Works well for sparse matrices - Although the Power Method is generally slower, this is not the case for extremely sparse matrices (which is true for H)
3. Matrix-free for storage and handling - The Power Method does not require matrix-matrix manipulations (which is time-laden for large matrices)
- The matrix is only accessed for vector-matrix multiplication (which is far less work than matrix-matrix multiplication)
4. Storage friendly - The only storage required is for the sparse matrix H (stored in sparse format, as mentioned previously), dangling node
vector a, and the current π(k)T vector.
5. Only 50 - 100 iterations are needed before iterates have converged - Algorithms whose run-times and computational efforts are linear in problem size are very fast and rare.
Although we will not go into the convergence theory, we would like to be able to see how the π(k)T converges to πT.
Activity 00309-06: Seeing the convergence of π
Purpose: To see the convergence of π within 50 iterations
Materials: Matlab
Estimated Time: 5 minutes
Instructions: (Clear Command Window)
1. Type your matrix A from Activity 00309-01 into Matlab (or double-click the matrix from the Command History).
2. Run the program rank_converge by typing:
[pi,time,numiter]=rank_converge(A) in the command window then press enter. The bars of the graph are the iterations.
Questions:
1. What do you see from the iterations?
2. The "numiter" variable returned in your Command Window is the number of iterations it took for pi to converge within 1x10-8 decimals of accuracy. How long did it take for the iterations to converge?
Now that you have learned about the basics of Google, there are a few adjustments Google can make in order to personalize the input for the more intelligent surfer.
This material is based upon work supported by National Science Foundation under Grant No. 0546622.
Any opinions, findings, and conclusions or recommendations expressed in this material are those of the
author and do not necessarily reflect the views of the National Science Foundation.